
We understand that many of our readers, like us, are hunkered down as the events around COVID-19 unfold. We hope you’re keeping as well as can be under the circumstances. Meanwhile, ABMI operations continue with a temporary shift of focus away from on-the-ground fieldwork and toward work that can be done digitally. To that end, the following piece, adapted from the latest iteration of our regular feature in BIOS Quarterly, the Alberta Society of Professional Biologists’ newsletter, seems topical.
Data management. Not exactly words to set the biologist’s heart aflutter, but maybe they should be.
Just ask Jonathan Pruitt. Since late January, the McMaster University arachnologist and Canada Research Chair has been at the center of a controversy over irregularities in his data on social spiders. Actually, regularities might be a better word, since it seems that entire blocks of values were repeated within the data as if they’d been copied and pasted. Whether intentional fraud or, as Pruitt contends, a failure of digital housekeeping, the controversy is a lesson in the importance of impeccable data management in an age of big data. For an operation like the ABMI whose main product is data, that lesson hits close to home.
It’s not just about convenience and organization. Kate Laskowski, a Pruitt collaborator directly impacted by his data problems, frames the issue as one of trust. From researchers to publishers to decision-makers or the general public, the entire scientific food chain relies on trust that the results are, in fact, trustworthy. For the ABMI, whose business is built on delivering credible data and data products, maintaining the trust of our clients and stakeholders is vital to our survival. In a time of information echo chambers, snap judgements, and fake news, trust is that much more fragile and valuable.

Snow geese are very poor at social distancing. Don’t be like snow geese. (Credit: Arnold Janz)
Biology was once a wholly observational science. Today, though most studies still begin with observations, additional techniques—experimentation, statistical analysis, and so on—are used to reveal patterns less visible to the eye. Observational breadth gives way to analytical depth, with many discoveries made possible by advances in number wrangling (spreadsheets, databases, ever-faster processors), and in analytical techniques that let researchers drill down and mine formerly unreachable seams of knowledge. As the ability to gather, sort, and work with data has expanded, so too have the datasets themselves. This is certainly true at the ABMI.
Despite these powerful tools, one constant remains: the fallibility of human researchers. If big data is increasingly inscrutable to all but digital eyes, so too are any errors that creep in and quietly ramify. As scientists work with larger and more unwieldy datasets, the work needed to maintain credibility has expanded in scope and importance. ‘Garbage in, garbage out’, they say in the computer world, and that’s true in biology as well. The cost of analytical power is the need for extra care and vigilance through rigorous, proactive data management. But data management is the scientific equivalent of eating fiber: it’s important, yet few are enthused by it.
At the ABMI, observation and data collection form the tip of the data management iceberg. The ABMI collects, processes, and manages terabytes of biodiversity data each year, across six distinct centers of operation and involving dozens of different staff members. As you might imagine, having such an extensive data supply chain means a lot of effort goes into maintaining data integrity. This is partly out of necessity and an abundance of caution, but also out of a sense that it’s time to re-imagine how people look at data management.
Here’s the thing. Scientists like analyzing and discovering, and data management activities can feel like chores—grit your teeth, get through them as fast as possible, and move on to the good stuff. But maybe that’s missing the point of the big data reality. Data management is no longer a peripheral chore but a vital part of the new research paradigm that deserves investment, innovation, and even celebration. Maybe it’s actually…interesting.
Good data management is multi-faceted and dynamic. Preventing errors at the outset (quality assurance; QA) and weeding them out or ensuring they don’t creep in downstream (quality control; QC) are different challenges—and effective data management has to address both. Moreover, data management practices need to grow and evolve along with the data. For example, ABMI field technicians enter raw data into tablets with customized interfaces that encourage standardization and make errors easier to see and correct, but this is only one step in the process. Long before that step, technicians receive extensive training in the ABMI’s field protocols; long after it, data are transferred from the tablets using data-loading scripts that minimize human error; and throughout the entire process, field coordinators and data management specialists monitor and verify. From QA groundwork through to the many fail-safes involved in QC and finally to preparation for public release, the ABMI’s data management policies take 115 pages just to summarize—that’s in addition to the 80+ standard operating procedure (SOP) documents that outline how each step is accomplished. As the ABMI’s monitoring program grows or incorporates new methods, these QA/QC processes are also updated, tested, and applied.
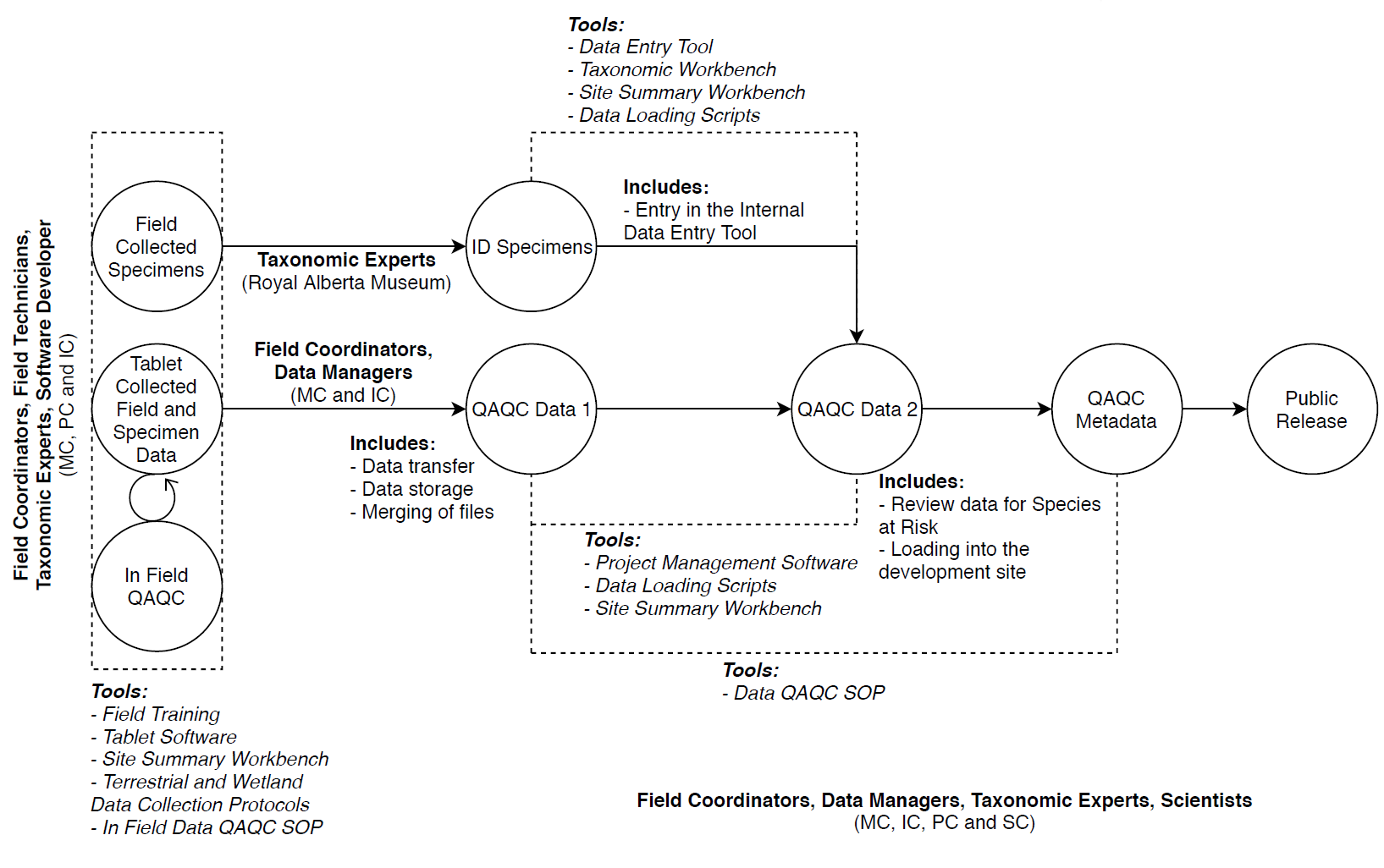
The data QA/QC process, AKA the most boring image at the ABMI…or is it the most interesting? Credit: Corrina Copp
There’s more. ABMI data are reviewed by both internal and external auditors, and regularly evaluated for relevance and accessibility. Naturally, data longevity and archiving must also be planned for and maintained, so that our ever-expanding datasets will always be available to those who need them. And we’re well aware that despite all these efforts, ABMI data will never be completely immune to error.
Until biological research is done by robots, there will be a human element to data collection and processing. That only underscores the need to strive for effective data management—to see it not as an inconvenience but an opportunity for innovation, creativity, and collaboration in pursuit of the most precious of scientific results: trust. That’s why we invest so much energy into getting it right, and why, like all ABMI data and publications, our QA/QC procedures are transparent and free for anyone to review. The work is never done but we hope that, as part of a growing movement, we’re helping to make data management a little less uncool.